Okay, I am going to argue or convince myself some of the interesting things about robot learning using two blobs. The blobs in our case are manifold for two skills in robot learning. But what is a manifold? It is a mathematical abstraction that specifies a complex geometric object embedded in higher-dimensional space in a lower-dimensional space. Basically, it states that most of the high-dimensional datasets can really be understood as lying on somekind of low-dimensional manifold (the lower dimension is also somtimes called intrinsic dimension). There are both theoretical and experimental explanations (Carlsson et al., 2008) for this.
Now, coming to our blobs, I will borrow some of the visualizations and ideas from Task and Motion Planning (TAMP) community for conveying my ideas. Assume that we live in a universe where we have a library of skills, each of which are independent and composable and we can use this collection of skills to solve any task. That’s a reasonable assumption!

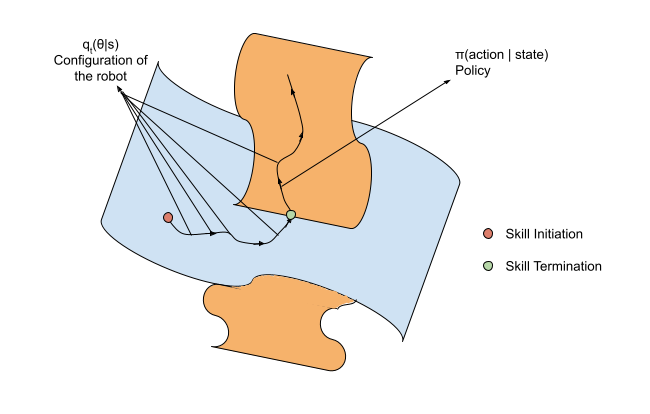
Let us say that we have a task at hand, say “Pick up this mug and place it on the table”. We can access the skills needed for this based on this natural language description of the task along with vision (scene description can be necessary sometimes). For this task, we need “Pick” skill and “Place” skill. Let a single-point on these manifolds describe the configuration of our robot, and a line along these manifolds represent a trajectory.
Composition of skills
We can think of composition of the skills as intersection of the corresponding manifolds in the task space. And the boundary of this intersection can be seen as configurations at which we can switch between these skills (mode in TAMP). Composing skills requires understanding how their manifolds connect or intersect.
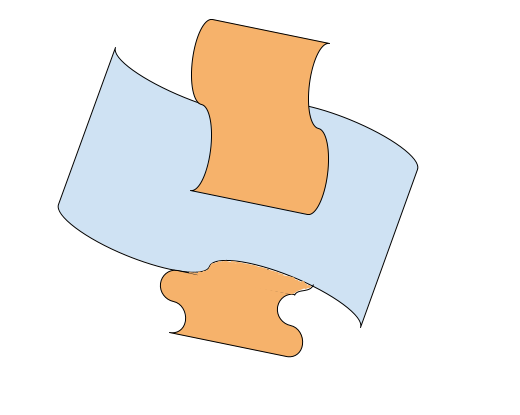
While LLMs and TAMP planners are very good at discretely planning steps, however, composing these discretes plans with continuous variables of skill configurations is probably one of the limitation for solving long-horizon robotics tasks. Now, the lure of training large models on large datasets with language conditioning for behavior cloning, is that, we are essentially teaching them how to move along this manifold by conditioning them on the states. So, each demonstrations is a line or trajectory along this manifold and our training set would be a bunch of lines along these planes starting and ending at different positions. Our hope is that once we map enough skills and compositions we are able to learn how these manifolds look like and how to compose some of the common manifolds. And we can apply the discrete planner like LLMs and condition on their output these trajectories and hope that we have a smooth trajectory able to accomplish the goal.
Although, I split the task into different skills and have a smooth trajectory from starting to end of the task, in reality this seperation is not very clear in complex cases. We can have multiple switches between the skills and also different skills can be needed/fetched dynamically during a task execution. That is why, I am not a huge fan of developing training seperate policies for seperate tasks because doing so can be extremely sample inefficient. A better idea would be to use a general policy as initialization for training a subsequent skill. You might think that this is akin to fine-tuning although fine-tuning is usually seen as worse than co-training (Fu & Zhao et al., 2024), however, I still think that we are yet to reach a conclusion on this.
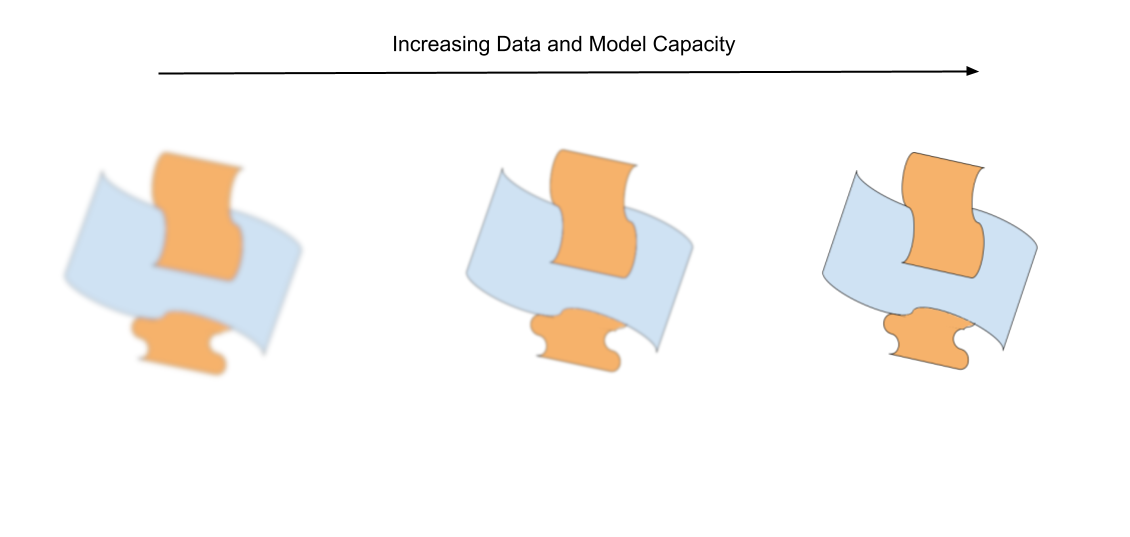
Model Size, Retrieval, Uncertainty and Resolution
I really like this analogy of connecting the scaling laws, retrieval and uncertainty to the resolution of the task-space manifolds. When you have a small model or a small dataset, the manifold is kinda blurry and you have a rough (noisy) esimate of where you are in the current task and how you move from their to a configuration where you can switch between skills. But as you increase your model-size as well as the dataset size, the resolution of the manifold increases as well. Now you will have a better (less noisy) estimate of your configuration and how to move from that configuration to the boundary of a different skill.
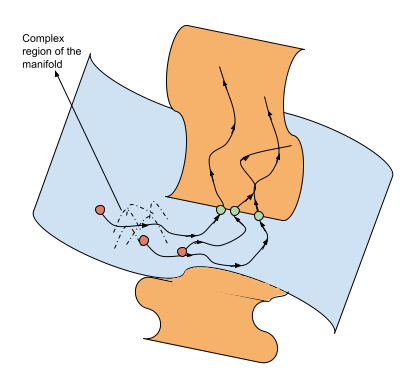
This is analogous to traditional uncertainty estimation in machine learning. When we talk about a “blurry” manifold in the context of smaller models or limited data, this blur can be interpreted as epistemic uncertainty - our model’s uncertainty due to limited knowledge. Just as traditional uncertainty estimation methods like ensemble variance or dropout sampling give us a spread of possible predictions, the blurriness of our manifold represents a distribution over possible configurations and trajectories. Higher resolution manifolds, achieved through larger models or more data, correspond to reduced epistemic uncertainty, giving us sharper estimates of where we are in the configuration space. This is analogous to how ensemble predictions tend to converge as we add more training data. However, just as aleatoric uncertainty (inherent system randomness) remains even with infinite data, certain regions of our skill manifolds might retain some inherent “blur” due to the fundamental variability in how certain skills can be executed. This is particularly evident near the boundaries where skills intersect, where multiple valid transition points might exist.
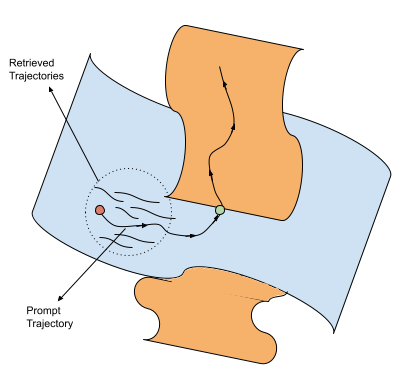
Similarly, we can also visualize Retrieval-based methods, albeit if we are retrieving some trajectories from a prior large dataset based on similarity metric, then it is similar to increasing the local resolution of the manifold (or reducing the uncertainty in our mapping from state to actions). By getting similar trajectories and finetuning on these demonstrations can increase the resolution of the manifold which inturn can allow for more accurate estimate and direction to move along the manifold for completing the tasks. However, the retrieval of trajectories is usually based on similarity metrics, which might result in a lot of redundant trajectories that might not be useful. This is mainly because similarity based metrics does not take into account the information gain from individual samples (Hubotter et al., 2024).
Interesting Problems
Thinking about the connection to Action-Horizon Increasing action prediction horizon seems to increase the success rate in general, upto a certain point. I believe that this is the property of certain boundaries being a bit more forgiving to overstepping the boundary or there might be a strong feedback that attracts the nearby configurations to the boundary (think of it as the dimension near the boundary dropping even further than the intrinsic dimension of the rest of the manifold). Can we verify this?
Extracting the Manifold information: If we train effective models that are able fit the target distribution effectively, can we use these model to extract information about the manifold? Extracting detailed information about the manifold can help in improved sampling and better estimate of local complexities of the manifold. The latter can be especially be helpful during dynamic test-time compute allocation (Graves et ., 2016, Dehghani et al., 2020, Banino et al., 2021).
Why does increasing the composition in the dataset can help in more compositions? A recent work (Zhao et al., 2024) has shown that “Fine-tuning on texts that compose a smaller number of skills leads to improvement of composing a larger number of skills”. Why is this? Are there any particular neuron connections or circuits that are responsible for composing the skills together?