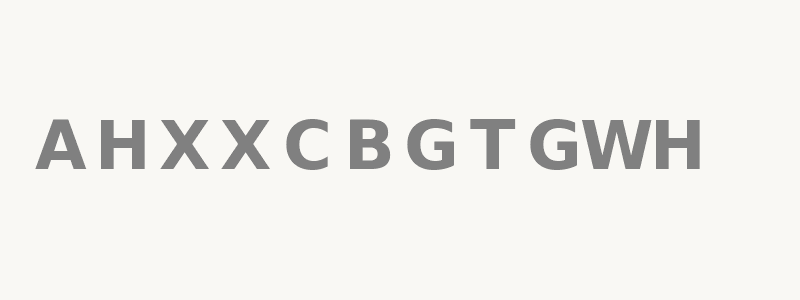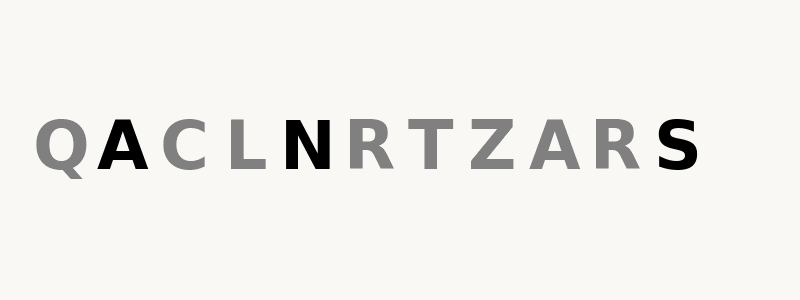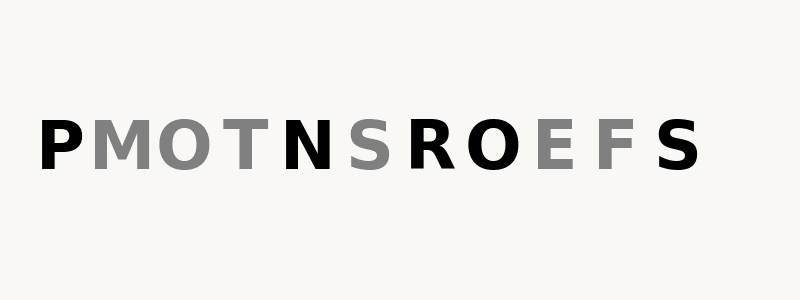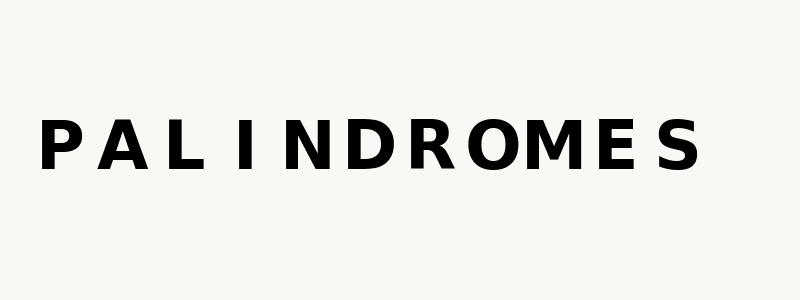
Recently, Alex Nichol wrote an article for producing palidromes using a specialized language model. But it was still an autoregressive model, and by the nature of modeling and tokenization these are (probably?) inherently limited and not particularly suited for producing palindromes. As he suggested, one way to overcome both of these limitations is to use a Byte-level Discrete Diffusion Language Model (DDLM). So, I decided to train a byte-level DDLM to see if it performs better than autoregressive LM in building palindromic sequence. Some examples:
Base-model : amma, elle, takkat, hannah, top pot, riaf fair, kazak, siris, markram, god dog, madam, level
Finetuned (longer sequences): stops tat spots, WARD II DRAW, drawer sees reward, peels sees sleep, a santa spins spins at nasa
Finetuned (almost there): Tuna peed Deep nut, AID WAS LIL PEES I DIR ADDOODDA RID I SEE LIL SAW DIA
I took the model from Score Entropy Discrete Diffusion (SEDD) and trained it from scratch without using tokenization on about 3GB of wikipedia data to see if it is able to produce faithful and long palindromes. They seem to be better :)¹
Dataset and Training
For the dataset, I took about 3GB from the English wikipedia dataset, removed all the special characters and numerics from the data and converted each UTF-8 character to its respective bytes, creating a vocabulary size of 259 (0-255, PAD, BOS, EOS). Now the spaces between the characters is an interesting choice, because later you will see how keeping the spaces might hinder my sampling strategy in producing faithful palindromes. I have a small ablation in the codebase, but for the main model I trained with the spaces intact. I use a sequence length of 32 characters, while making sure that each sequence contains full words. Rather than truncating words I pad the sequence if I cannot fit one in.
For training I don’t do anything fancy, I use the same model from SEDD which is a Diffusion Transformer with 91M parameters along with a sequence length of 32 with AdamW optimizer (Muon didn’t seem to be better:( ), with only using unicode characters rather than their tokenization scheme. I trained both absorb and uniform models (see the paper for differences). For the same amount of training iterations, uniform seem to produce a tiny bit more palindromic sequence without fine-tuning or palindromic constraint during sampling, more on this later.
Sampling
This is an interesting one, there are many interesting ways to induce palindromic structure in the model. Naively, one can do rejection sampling, which produced palindromes at around 0.1% of time and mostly uninteresting. Because the whole model itself is differentiable, we can add a “palindromic loss” during sampling steps to guide the sampling towards palindromes, however, balancing the strength of guidance to produce natural samples vs uninteresting samples is a bit tricky. One simple method is to average the score across symetric positions during denoising. Because we are in discrete domain, each of the position starts from the same character (MASK) at the beginning (in the absorb model), so averaging the score during denoising produces similar characters at the end. While, this was an effective strategy for one-word palindromes, one limitation of this is that when we want multiple-words palindromes these can be asymmetric i.e., palindromes have different word boundaries on each side (‘tuna nut’ would not possible with this scheme, whereas ‘tun a nut’ will be possible), while trying something like randomly applying this averaging might solve this, however, I don’t have exact metrics to see if it helps. One method is to remove the spaces while creating the dataset, however, it seems to make learning difficult and wasn’t much better either, maybe it requires more compute and smaller sequence length.
If someone has a better idea then I have the pre-trained model uploaded on huggingface!
Fine-tuning
A collected some palindromes and fine-tuned the model to see if it increases models ability to produce such, and by just eyeballing it does seem to improve!! Especially, when I increase the length of sequence, the models seem to be good at composing palindromes in the fine-tuning dataset, however, sometimes they fail to maintain natural sounding sentence or understand that sometimes adding two palindromes might not result in a palindrome (see fine-tuned examples above)! But it was interesting to see. Almost 50% of the time, although the pre-trained model produces more number of palindromes, but most of them are syntatically not correct.
Absorb vs Uniform Models

Absorb Model

Uniform Model
SEDD offers two transition matrix variants that differ in their training dynamics. The absorbing model learns to fill in MASK tokens (similar to BERT’s approach), while the uniform model learns to denoise from random vocabulary tokens. During training, the absorbing model transitions all tokens to MASK states, whereas the uniform model recreates a more chaotic noise approach by allowing any token to become any other token. During my experiments, the uniform model produced palindromes more frequently during sampling (I didn’t measure any statistical metrics to be sure about this but just from 100 random samples), despite both models having around similar perplexity on random sequences (in the paper). One probable reason is that the uniform model allows more exploratory denoising process allowing for greater token oscillation and refinement, which might probably be better suited for producing palindromes. The absorbing model’s “fill-in-the-blank” approach appears more deterministic and may commit too early to non-palindromic token choices, reducing its ability to satisfy the global palindromic constraint.
Closing thoughts: Overall, it was an interesting experiment! Most of the language models seem to have hard-time in producing novel, coherent, long-sequences of palindromes. One part of the problem is of-course tokenization, another part of the problem is able to think about the global structure of the sequence before committing to a particular token. I do think that LLMs are pretty capable in the latter though, because they are pretty good at coding which also requires a long, coherent thinking before committing to a particular token. However, I do think that the ability to edit a token after it has been produced can be much more helpful not just in palindromes but also in coding. Reasoning models kinda do this, but I feel like diffusion models are much better suited for this. It would have been interesting to compare byte-level auto-regressive model to byte-level diffusion model for palindromes, maybe I will do it in the future!!